ECMP and Stateful Services
 It’s not new, this topic has already been discussed many times before, examples are here, here, here and here. When NSX Edges are configured in ECMP mode, none of the stateful services like VPN, NAT or Load Balancing are supported.
It’s not new, this topic has already been discussed many times before, examples are here, here, here and here. When NSX Edges are configured in ECMP mode, none of the stateful services like VPN, NAT or Load Balancing are supported.
From NSX Design Guide:
In ECMP mode, only routing service is available. Stateful services cannot be supported due to asymmetric routing inherent in ECMP-based forwarding.
Even if you didn’t read documentation, but have networking skills, you’d know that protocols like NAT need to track network session state and even if you configure the same NAT rule on all of your ECMP-enabled edges, it won’t work, because due to ECMP, traffic can flow through one ESG on ingress and another ESG on egress. Since NAT tables are not synchronized, ESGs won’t be able to find the corresponding network flow in translation table and will drop the traffic.
ECMP and Firewall
But there’s another issue that doesn’t always come across or simply get forgotten about. You can deploy ESGs in ECMP mode, not configure any of the stateful services like VPN, NAT or LB, but still get network communication issues. Why? Because when you deploy an ESG, you always end up with firewall in enabled state. Firewall is also considered a stateful service.
From VVD 5.1 documentation:
SDDC-VISDN-032: For all ESGs deployed as ECMP North-South routers, disable the firewall. Use of ECMP on the ESGs is a requirement. Leaving the firewall enabled, even in allow all traffic mode, results in sporadic network connectivity. Services such as NAT and load balancing cannot be used when the firewall is disabled.
In fact, firewall is what actually tracks sessions and drops packets that don’t match existing network flows, not NAT itself. That’s also the reason why services like NAT and LB don’t work without firewall being enabled.
It often throws people off, because even having no rules in the firewall and setting default policy to accept will not prevent this issue from happening.
Demo
Here is a quick demonstration. I’m trying to establish an SSH session to a VM connected to a DLR behind two ESGs in ECMP mode.

I’m showing packet debug on both ESGs using the following command:
> debug packet display follow interface vNic_1 port_22
As you can see ingress traffic goes through E1 and egress traffic goes through E2:

E1: Packet Capture

E2: Packet Capture
Since session originated on E1, E2 interprets packets as invalid and immediately drops them:

From NSX Troubleshooting Guide:
Check for an incrementing value of a DROP invalid rule in the POST_ROUTING section of the show firewall command. Typical reasons include:
- Asymmetric routing issues
- …
Conclusion
It’s easy to end up in this situation, because firewall is enabled by default on a newly deployed ESG. And it’s hard to troubleshoot this issue, since it’s not quite obvious what’s actually going on unless you’ve already worked with ECMP before. So the best advice in this case is just to remember, if you want to use ECMP in NSX, make sure to disable firewall on ECMP-enabled ESGs. Use distributed firewall (DFW) instead.
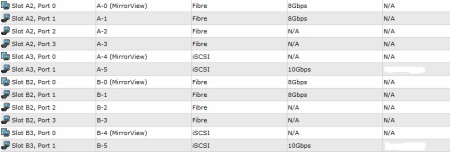
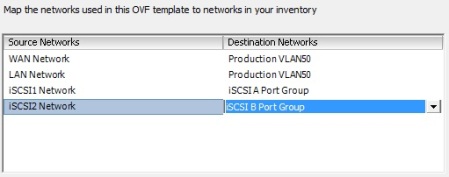
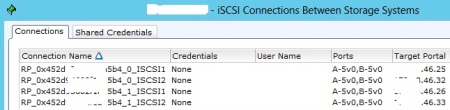
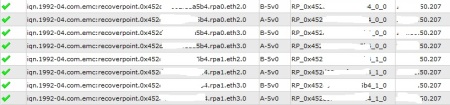
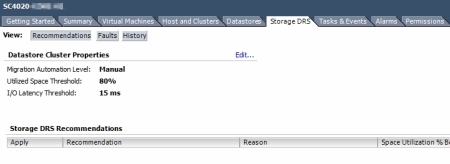
 If you happen to have your vSphere cluster to be licensed with Enterprise Plus edition, you may be aware of some of the advanced storage management features it includes, such as Storage DRS and Profile-Driven Storage.
If you happen to have your vSphere cluster to be licensed with Enterprise Plus edition, you may be aware of some of the advanced storage management features it includes, such as Storage DRS and Profile-Driven Storage.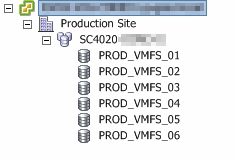
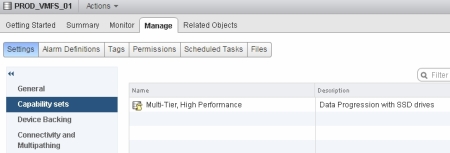
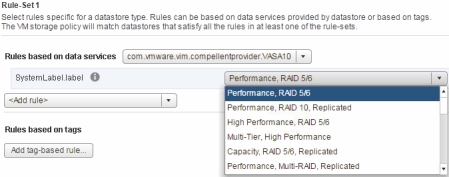
 RecoverPoint is a great storage replication product, which supports Continuous Data Protection (CDP) and gives you RPO figures measured in second compared to a standard asynchronous storage-based replication solutions, where RPO is measured in minutes or even hours.
RecoverPoint is a great storage replication product, which supports Continuous Data Protection (CDP) and gives you RPO figures measured in second compared to a standard asynchronous storage-based replication solutions, where RPO is measured in minutes or even hours.