Connect-VIServer is a PowerCLI cmdlet which most of the PowerCLI scripts out there start with. It creates a connection to a vCenter server, which you can then use to run queries against a particular vSphere environment.
Connect-VIServer is a PowerCLI cmdlet which most of the PowerCLI scripts out there start with. It creates a connection to a vCenter server, which you can then use to run queries against a particular vSphere environment.
If you only need one vCenter connection, you don’t need to worry about how your subsequent PowerCLI cmdlets are ordered. They will all use this single vCenter by default for all requests. But if you need multiple simultaneous connections, you have to be more careful with you code or you can accidentally end up running commands against a wrong vCenter. Not a situation you want to find yourself in, especially if you’re making changes to the environment.
Goal of this blog post is to explain PowerCLI behaviour, when multiple vCenter connections are used. And how to best write your code to avoid common mistakes.
vCenter server parameter
If you are connected to more than one vCenter, the easiest way to specify which vCenter to use in a particular PowerCLI cmdlet is by using the -Server parameter. For example:
Get-VM -Server vcenter1.domain.local
By doing so, you will avoid any ambiguity in your code, since vCenter is always specified explicitly. This is the theory. In reality, I find, you will always have that one command where you forgot to provide -Server parameter, which will cause problems when you least expect it.
DefaultVIServer variable
If you’ve done any PowerCLI scripting before, you’ve most likely come across the $global:DefaultVIServer variable. When you connect to a vCenter using Connect-VIServer cmdlet, DefaultVIServer variable is set to that vCenter name. That way when you run PowerCLI cmdlets without using -Server parameter, they implicitly use vCenter from the DefaultVIServer variable as a target for the query. When you disconnect from the vCenter using Disconnect-VIServer, this variable is emptied.
The challenge with this approach is that the DefaultVIServer variable can only hold one vCenter name. If you connect/disconnect to/from multiple vCenter servers, you may end up in a situation where DefaultVIServer variable becomes empty, even though you still have an active vCenter connection. It’s easier to demonstrate it in the following script output:
Connecting to vCenter server vcenter1.domain.local
DefaultVIServer value: vcenter1.domain.local
Connecting to vCenter server vcenter2.domain.local
DefaultVIServer value: vcenter2.domain.local
Disconnecting from vCenter server vcenter2.domain.local
DefaultVIServer value:
Get-VM : 29/11/2019 6:17:41 PM Get-VM You are not currently connected to any servers. Please connect first using a Connect cmdlet.
As you can see, after we disconnect from the current default vCenter server vcenter2.domain.local, the variable becomes blank, until we connect to any other vCenter again. As a result, Get-VM cmdlet fails.
The error message is misleading. Connection is there and you can still run commands against the vcenter1.domain.local by specifying it in the -Server parameter. However, it defeats the purpose of DefaultVIServer variable, when using multiple simultaneous vCenter connections.
There is a way to fix that.
DefaultVIServer mode
This leads us up to the third option – changing DefaultVIServer mode. PowerCLI supports multiple default vCenter servers if you change DefaultVIServer to Multiple (default is Single):
Set-PowerCLIConfiguration -DefaultVIServerMode Multiple
As a result of this change, PowerCLI will start using DefaultVIServers array, which tracks all currently connected vCenters.
There are two implications of using Multiple connection mode:
- If you run a PowerCLI cmdlet without the -Server parameter, it will run against all connected vCenters at the same time – which is fine, as long as this is what you want.
- If you expect other users to run this script and they use Single connection mode, it can break your script. If that’s the case, make sure to explicitly set DefaultVIServer mode in the beginning of your script to avoid any unexpected behaviour.
Conclusion
Each option has its pros and cons. It’s up to you to choose what works best in your particular situation. But if you asked me, I would recommend disconnecting vCenter server session as soon as you no longer needed it. That way you can avoid any potential ambiguity in your code. Use multiple simultaneous vCenter connections only if you absolutely need it.












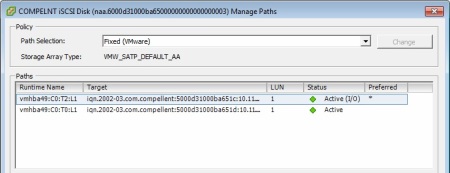
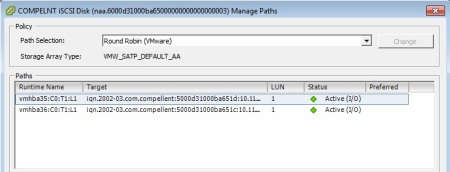
 If you’ve ever worked with Dell Compellent storage arrays you may have noticed that when you initially connect it to a VMware ESXi host, by default VMware Native Multipathing Plugin (NMP) uses Fixed Path Selection Policy (PSP) for all connected LUNs. And if you have two ports on each of the controllers connected to your storage area network (be it iSCSI or FC), then you’re wasting half of your bandwidth.
If you’ve ever worked with Dell Compellent storage arrays you may have noticed that when you initially connect it to a VMware ESXi host, by default VMware Native Multipathing Plugin (NMP) uses Fixed Path Selection Policy (PSP) for all connected LUNs. And if you have two ports on each of the controllers connected to your storage area network (be it iSCSI or FC), then you’re wasting half of your bandwidth.